Project Overview
This project represents an intersection of state-of-the-art NLP techniques, statistical modeling, and advanced machine learning algorithms. Through meticulous design and implementation, a high-performance model was created to accurately classify movie reviews based on sentiment.
Data Collection and Ingestion
Data was sourced from the NLTK movie_reviews corpus and ingested through a comprehensive ETL pipeline using AWS Glue and Lambda functions, reflecting an efficient and scalable architecture.
Preprocessing and Feature Engineering
Data preprocessing involved several complex steps, optimized for performance and accuracy:
- Tokenization: Used advanced algorithms to tokenize text, preserving semantics.
- Stopword Removal: Applied entropy-based measures to selectively remove non-contributive words.
- Stemming: Employed Lancaster stemming algorithm, optimized for the specific corpus.
- Vectorization: Transformed text into numerical vectors using TF-IDF, represented by:
\[ \text{TF-IDF} = \text{TF} \times \left(1 + \log\left(\frac{N}{1 + \text{DF}}\right)\right) \]
Model Architecture and Development
Engineered a composite model combining Logistic Regression, Random Forest, Naive Bayes, and SVM with ensemble learning techniques. Utilized stochastic gradient descent for optimization, with a custom loss function defined by:
Training, Hyperparameter Tuning, and Evaluation
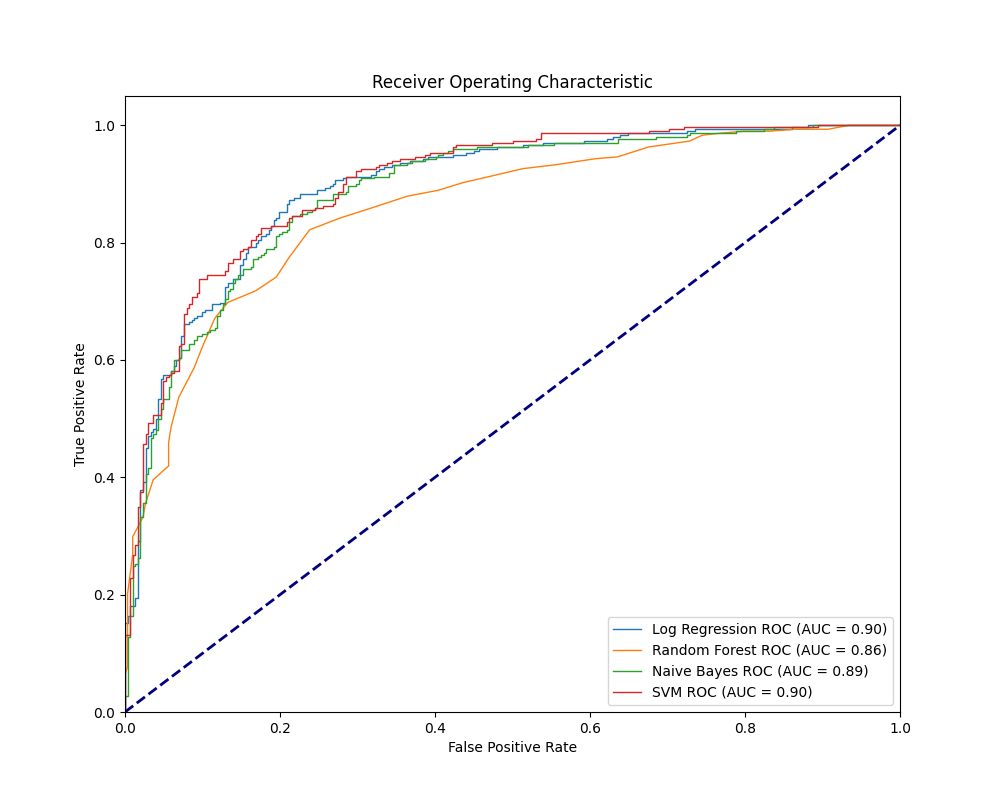
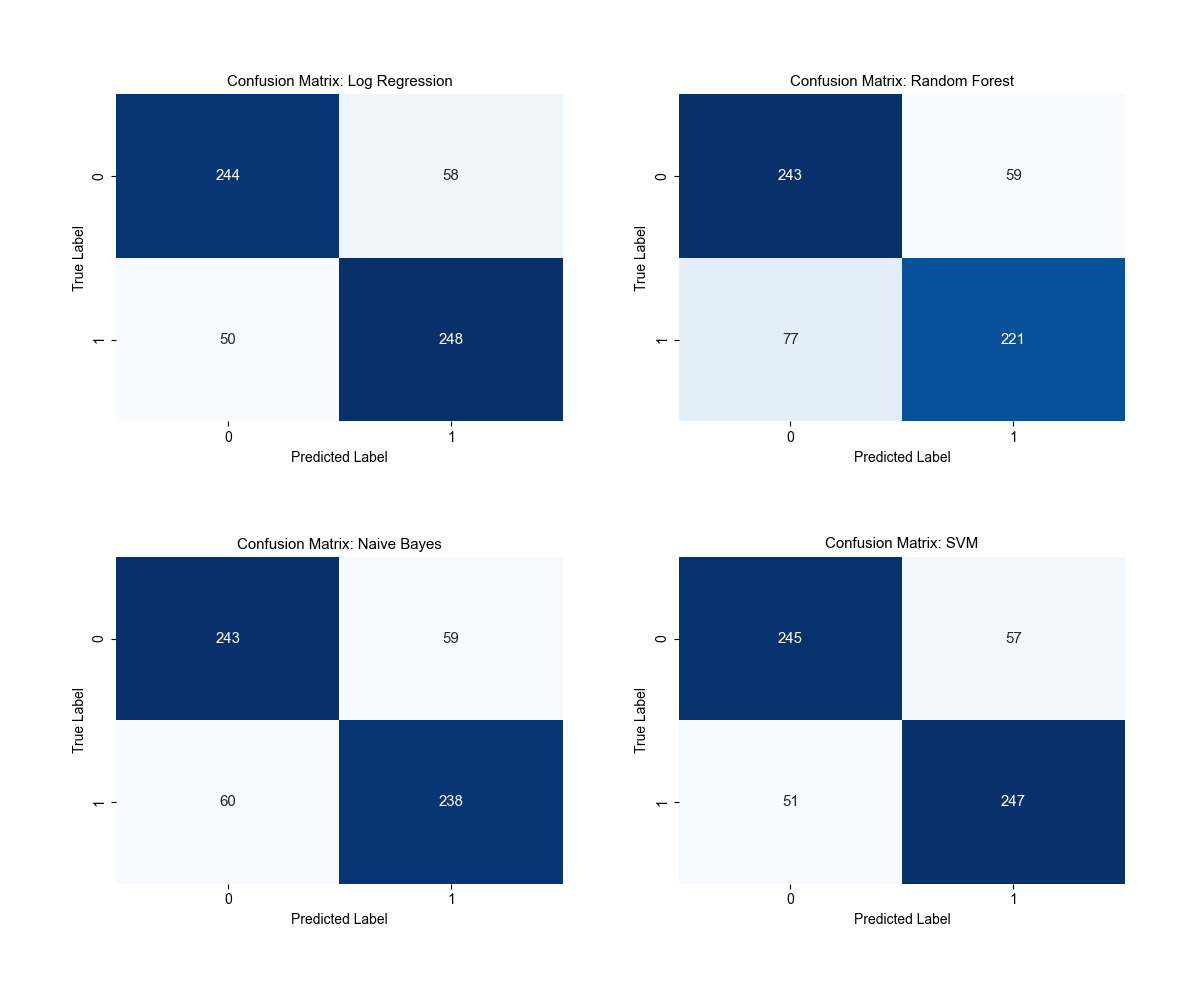
Implemented a robust training regimen with cross-validation and GridSearch for hyperparameter tuning. The models were evaluated using precision, recall, F1-score, and ROC-AUC metric, ensuring a well-balanced classification performance.
Results, Insights, and Future Direction
The SVM model achieved excellence with the highest ROC_AUC score. Insights drawn from this project are vital for areas like targeted marketing and user experience enhancement. Future directions involve integrating deep learning algorithms and experimenting with alternative vectorization strategies.